Autonomous Rover
Model
The model is a semantic segmentation network trained to identify and delineate road surfaces in visual imagery. It accepts raw input images and generates pixel-level binary masks isolating drivable regions. Trained specifically on road scenes from the Sant Longowal Institute of Engineering and Technology (SLIET) campus, the model is tailored for high accuracy in structured and semi-structured environments. Leveraging YOLOv8’s transformer-enhanced backbone, it ensures precise spatial localization, efficient inference, and robust generalization under varying lighting and terrain conditions.
images
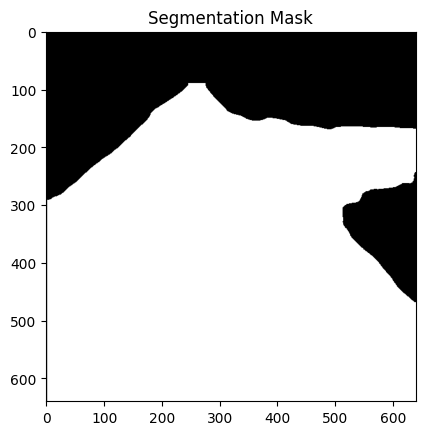
mask from our model

model early stage outputs
System Specs
Kaggle basic